Qualcomm® AI Hub
Qualcomm® AI Hub Workbench 可協助在裝置上針對視覺、音訊、語音及多模態使用案例,進行機器學習模型的最佳化、驗證與部署。
使用 Qualcomm® AI Hub Workbench,您可以:
在設備上分析模型以獲取詳細的指標,包括運行時間、加載時間和計算單元利用率。
通過在設備上進行推理來驗證數值正確性。
可輕鬆使用 Qualcomm® AI Runtime (運用 QNN API)、TensorFlow Lite 或 ONNX Runtime 來部署模型。
備註
QAIRT(Qualcomm® AI Runtime)是整體 SDK,並涵蓋 Qualcomm® AI Engine Direct (QNN)。Qualcomm® AI Hub Workbench 在整體 SDK 與版本管理方面參照 QAIRT,而在裝置上目前使用的執行階段 API 與工具方面則參照 QNN。
Qualcomm® AI Hub Models 是我們的預先最佳化模型集合,用來協助我們了解在 Qualcomm® 裝置上執行各種模型的效能特性。我們每隔幾週會使用 Qualcomm® AI Hub Workbench 在 Qualcomm® 裝置上進行編譯、效能分析及推論。如果您正在尋找一個入門模型,請務必查看它們!
Qualcomm® AI Hub Apps 是我們的範例應用程式集合,用於協助將 Qualcomm® AI Hub Models 部署至裝置端。若要設定您所需的執行環境以符合效能指標,並部署從 Qualcomm® AI Hub Workbench 取得的模型資產,您可以參考 Qualcomm® AI Hub Apps。
它是如何運作的?
Qualcomm® AI Hub Workbench 會自動處理模型從來源框架到裝置執行環境的轉換,並套用硬體感知的最佳化,同時執行實體效能與數值驗證。系統會自動在雲端配置裝置,以進行裝置端的效能分析與推論。下圖顯示使用 Qualcomm® AI Hub 分析模型的步驟。
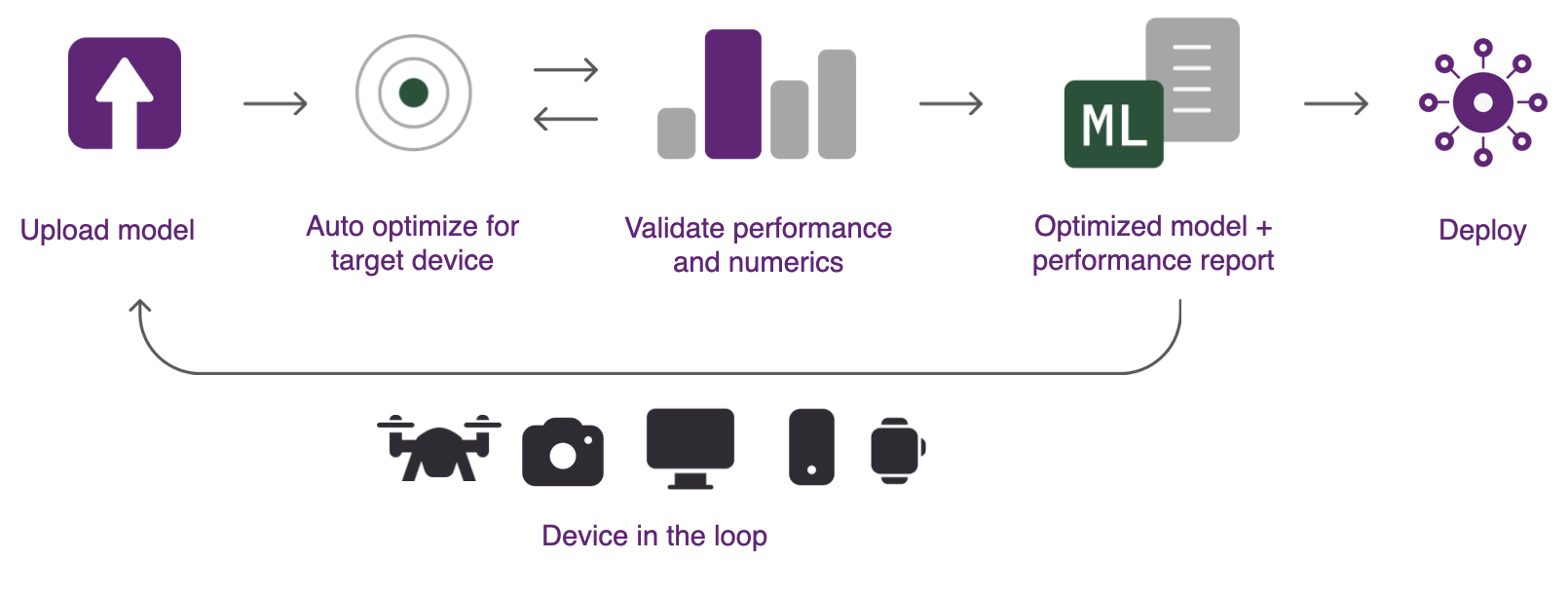
要使用 Qualcomm® AI Hub Workbench,您需要具備以下條件:
一個訓練好的模型,可以是 PyTorch、TorchScript、ONNX 或 TensorFlow Lite 格式。
對部署目標的工作知識。這可以是特定設備(例如,Samsung Galaxy S23 Ultra)或一系列設備。
以下三個步驟可用於將訓練好的模型部署到 Qualcomm® 設備:
- 步驟 1:優化設備上的執行
Qualcomm® AI Hub Workbench 包含一組代管的編譯器工具,可針對所選的目標平台最佳化已訓練的模型。接著會進行硬體感知最佳化,以確保目標硬體獲得最佳利用。模型可最佳化後部署到 Qualcomm® AI Runtime (運用 QNN API)、TensorFlow Lite 或 ONNX Runtime。所有格式轉換都會自動處理。
- 步驟 2:執行設備上的推理
系統可以在實體設備上運行編譯的模型,以收集指標,例如模型層到計算單元的映射、推理延遲和峰值內存使用量。這些工具還可以使用您的輸入數據運行模型,以驗證數值正確性。所有分析均在雲端自動配置的實體硬件上進行。
- 步驟 3:部署
模型結果會顯示在 Qualcomm® AI Hub Workbench 上,提供深入洞察以了解模型效能並找出進一步改進的機會。經過最佳化的模型可部署至多種平台。請查看 Qualcomm® AI Hub Apps,以針對特定使用案例逐步了解此流程。
目錄