Qualcomm® AI Hub
Qualcomm® AI Hub Workbench は、ビジョン、オーディオ、音声、マルチモーダルのユースケースにおいて、機械学習モデルをオンデバイスで最適化、検証、デプロイするのに役立ちます。
Qualcomm® AI Hub Workbench を使用すると、次のことができます:
PyTorch や ONNX などのフレームワークから学習済みモデルを Qualcomm® デバイス上で最適化されたオンデバイスパフォーマンスに変換します。
オンデバイスでモデルをプロファイルして、ランタイム、ロード時間、計算ユニットの利用率などの詳細なメトリクスを取得します。
オンデバイス推論を実行して数値的な正確性を検証します。
Qualcomm® AI Engine Direct, TensorFlow Lite, または ONNX Runtime を使用してモデルを簡単に展開します。
Qualcomm® AI Hub Models は、 Qualcomm® デバイス上で動作する幅広いモデルの性能特性を理解するために使用する、事前に最適化されたモデルのコレクションです。私たちは、 Qualcomm® AI Hub Workbench を使用して、 Qualcomm® デバイス上でモデルをコンパイル、プロファイル、推論を数週間ごとに実行しています。開始するモデルを探している場合は、ぜひチェックしてください!
Qualcomm® AI Hub Apps は、 Qualcomm® AI Hub Models をデバイス上で動作させるためのサンプルアプリケーションのコレクションです。パフォーマンス指標に合わせて希望するランタイムを設定し、 Qualcomm® AI Hub Workbench から取得したモデル資産をデプロイするには、 Qualcomm® AI Hub Apps を参照できます。
それはどのように機能しますか?
Qualcomm® AI Hub Workbench は、ソースフレームワークからデバイスランタイムへのモデル変換を自動的に処理し、ハードウェアに応じた最適化を適用し、物理的な性能および数値検証を実行します。システムは、オンデバイスのプロファイリングと推論のためにクラウド上でデバイスを自動的にプロビジョニングします。次の画像は、 Qualcomm® AI Hub を使用してモデルを分析するための手順を示しています。
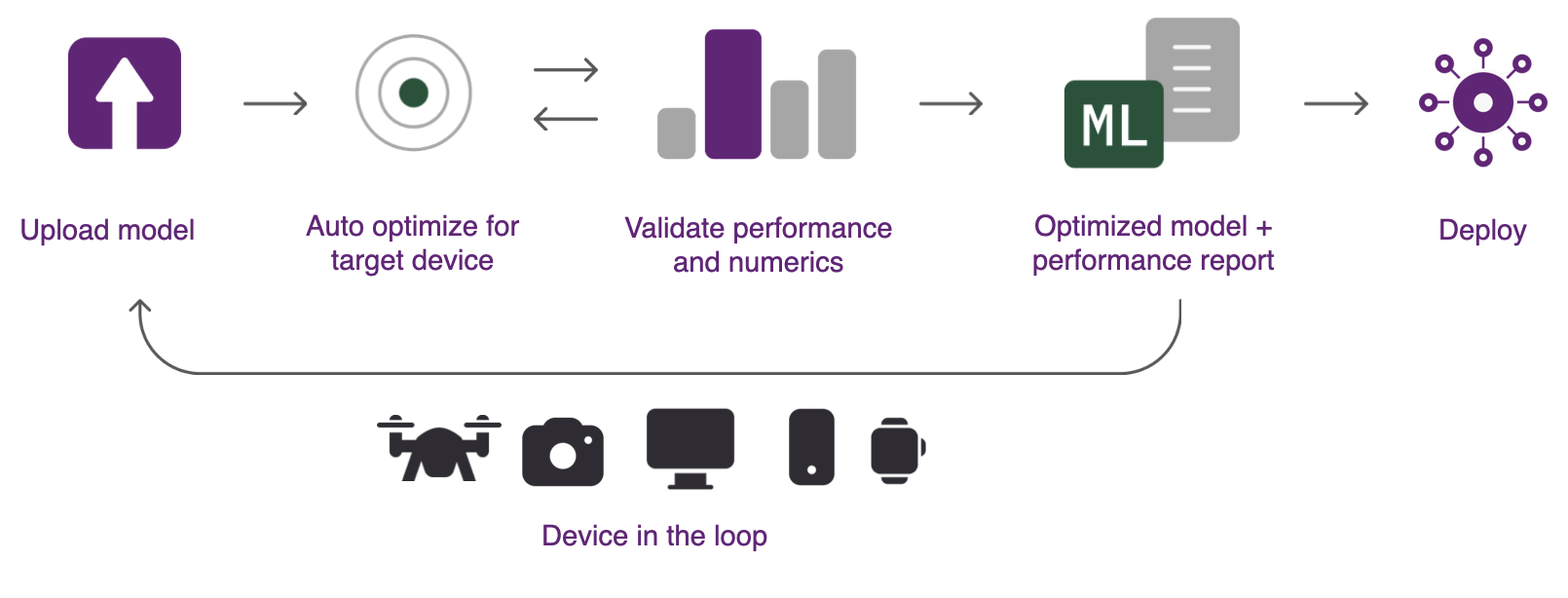
Qualcomm® AI Hub Workbench を使用するには、次のものが必要です:
PyTorch, TorchScript, ONNX または TensorFlow Lite 形式の学習済みモデル。
デプロイメントターゲットに関する実務的な知識が必要です。これは、特定のデバイス(例:Samsung Galaxy S23 Ultra)または複数のデバイス範囲を指します。
学習済みモデルを|qti|デバイスに展開するために使用できる次の3つのステップ:
- ステップ1:オンデバイス実行のための最適化
Qualcomm® AI Hub Workbench には、選択したターゲットプラットフォーム向けに学習済みモデルを最適化できるホスト型コンパイラツールのコレクションが含まれています。その後、ターゲットハードウェアを最大限に活用するために、ハードウェアに応じた最適化が実行されます。モデルは、Qualcomm® AI Engine Direct 、TensorFlow Lite 、または ONNX Runtime のいずれかにデプロイするために最適化できます。すべてのフォーマット変換は自動的に処理されます。
- ステップ2:オンデバイスの推論を実行
システムは、モデルレイヤーの計算ユニットへのマッピング、推論レイテンシー、ピークメモリ使用量などのメトリクスを収集するために物理デバイス上でコンパイル済みモデルを実行できます。ツールは、数値的な正確性を検証するために入力データを使用してモデルを実行することもできます。すべての分析はクラウドで自動的にプロビジョニングされた実際のハードウェアで行われます。
- ステップ3:デプロイ
モデルの結果は Qualcomm® AI Hub Workbench に表示され、モデルの性能を理解し、さらなる改善の機会を把握するためのインサイトを提供します。最適化されたモデルは、さまざまなプラットフォームへのデプロイが可能です。具体的なユースケースに沿ってこのプロセスを確認するには、 Qualcomm® AI Hub Apps をチェックしてください。
目次